Начало работы с Managed ClickStack
Самый простой способ начать — развернуть Managed ClickStack в ClickHouse Cloud, что обеспечивает полностью управляемый, безопасный бекенд при сохранении полного контроля над ингестией, схемой и обсервабилити-процессами. Это устраняет необходимость самостоятельной эксплуатации ClickHouse и даёт ряд преимуществ:
- Автоматическое масштабирование вычислительных ресурсов независимо от хранилища
- Низкая стоимость и практически неограниченный срок хранения на основе объектного хранилища
- Возможность независимо изолировать нагрузки чтения и записи с помощью warehouses
- Интегрированная аутентификация
- Автоматизированные резервные копии
- Функции безопасности и соответствия требованиям
- Бесшовные обновления
Зарегистрируйтесь в ClickHouse Cloud
Чтобы создать сервис Managed ClickStack в ClickHouse Cloud, сначала выполните первый шаг из руководства по быстрому старту ClickHouse Cloud.
Мы рекомендуем тариф Scale для большинства нагрузок ClickStack. Выберите тариф Enterprise, если вам требуются расширенные функции безопасности, такие как SAML, CMEK или соответствие требованиям HIPAA. Он также предлагает индивидуальные профили оборудования для очень крупных развертываний ClickStack. В таких случаях мы рекомендуем связаться со службой поддержки.
Выберите поставщика Cloud и регион.
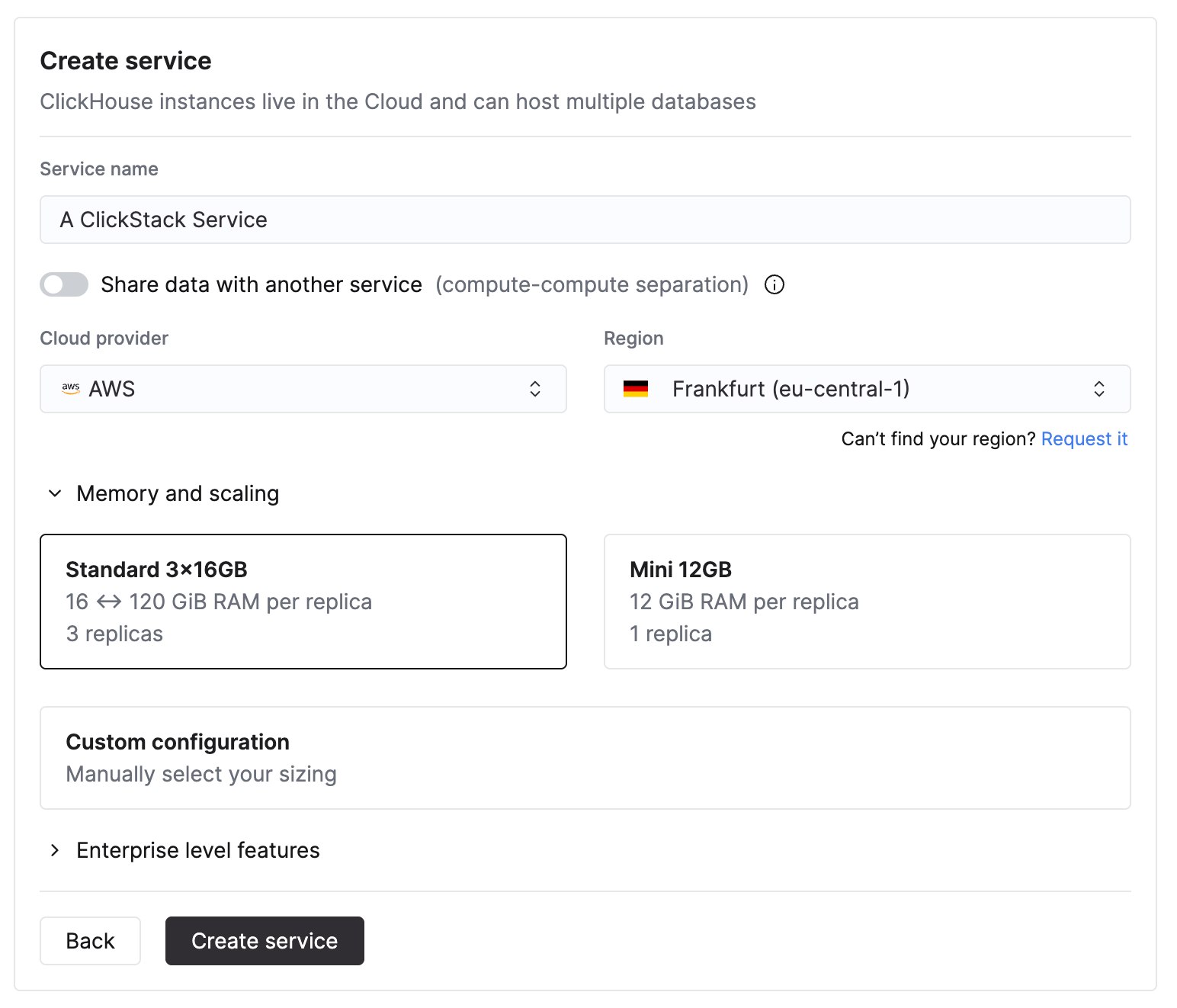
При указании ресурсов CPU и памяти оценивайте их, исходя из ожидаемой пропускной способности ингестии ClickStack. Таблица ниже поможет подобрать размер этих ресурсов.
| Месячный объём ингестии | Рекомендуемые вычислительные ресурсы |
|---|---|
| < 10 TB / месяц | 2 vCPU × 3 реплики |
| 10–50 TB / месяц | 4 vCPU × 3 реплики |
| 50–100 TB / месяц | 8 vCPU × 3 реплики |
| 100–500 TB / месяц | 30 vCPU × 3 реплики |
| 1 PB+ / месяц | 59 vCPU × 3 реплики |
Эти рекомендации основаны на следующих предположениях:
- Объём данных относится к несжатому объёму ингестии в месяц и применяется как к логам, так и к трейсам.
- Характер запросов типичен для сценариев обсервабилити, при этом большинство запросов нацелены на свежие данные, обычно за последние 24 часа.
- Ингестия относительно равномерна в течение месяца. Если вы ожидаете всплески трафика или пики нагрузки, следует заложить дополнительный резерв.
- Хранилище обрабатывается отдельно через объектное хранилище ClickHouse Cloud и не является ограничивающим фактором для периода удержания данных. Предполагается, что данные, хранящиеся дольше, запрашиваются редко.
Для шаблонов доступа, которые регулярно запрашивают данные за длительные периоды, выполняют тяжёлые агрегации или поддерживают большое число одновременных пользователей, может потребоваться больше вычислительных ресурсов.
Хотя две реплики могут удовлетворять требованиям по CPU и памяти для заданной пропускной способности ингестии, мы рекомендуем по возможности использовать три реплики, чтобы сохранить ту же общую ёмкость и повысить отказоустойчивость сервиса.
Эти значения являются лишь оценками и должны использоваться как начальная база. Фактические требования зависят от сложности запросов, уровня параллелизма, политик удержания и вариаций пропускной способности ингестии. Всегда контролируйте использование ресурсов и масштабируйте по мере необходимости.
После того как вы укажете требования, подготовка вашего управляемого сервиса ClickStack займёт несколько минут. Пока идёт подготовка, вы можете изучить остальную часть консоли ClickHouse Cloud.
После завершения подготовки опция 'ClickStack' в левом меню будет доступна.
Настройте ингестию
После того как ваш сервис будет создан, убедитесь, что этот сервис выбран, и нажмите «ClickStack» в левом меню.
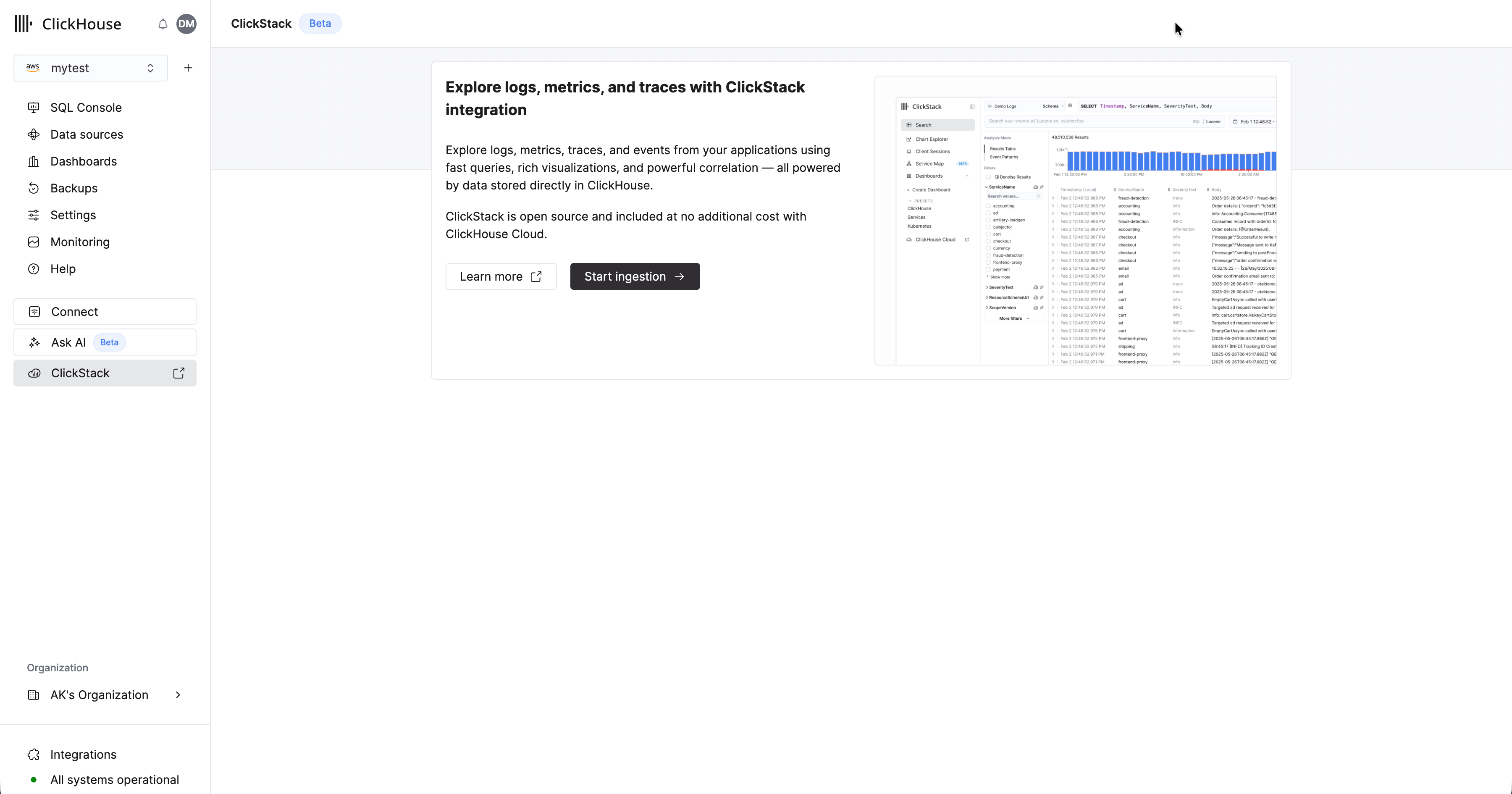
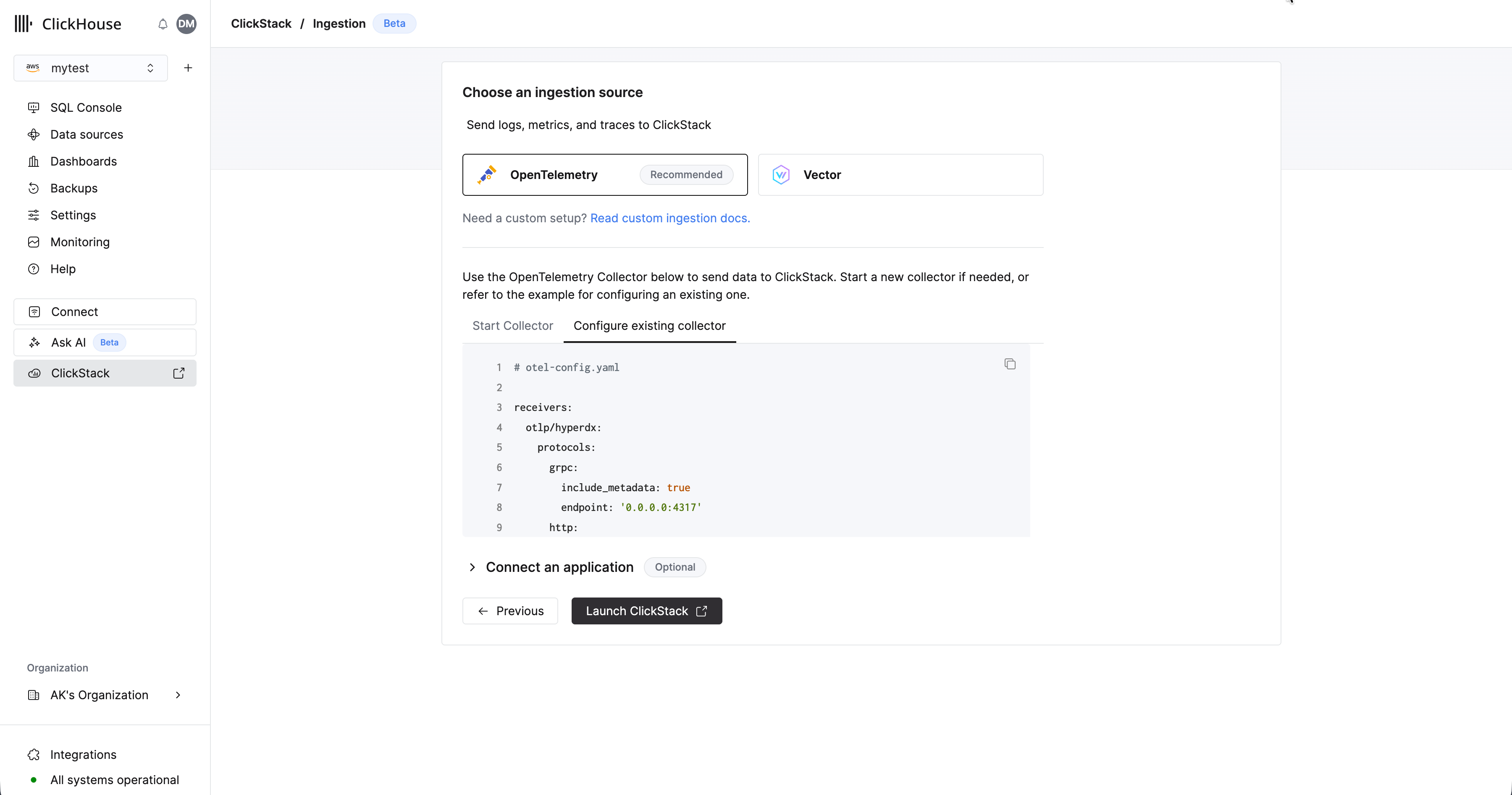
Выберите "Начать ингестию", после чего вам будет предложено выбрать источник ингестии. Управляемый ClickStack поддерживает OpenTelemetry и Vector как основные источники ингестии. Однако пользователи также могут отправлять данные напрямую в ClickHouse в собственной схеме, используя любую из интеграций, поддерживаемых ClickHouse Cloud.
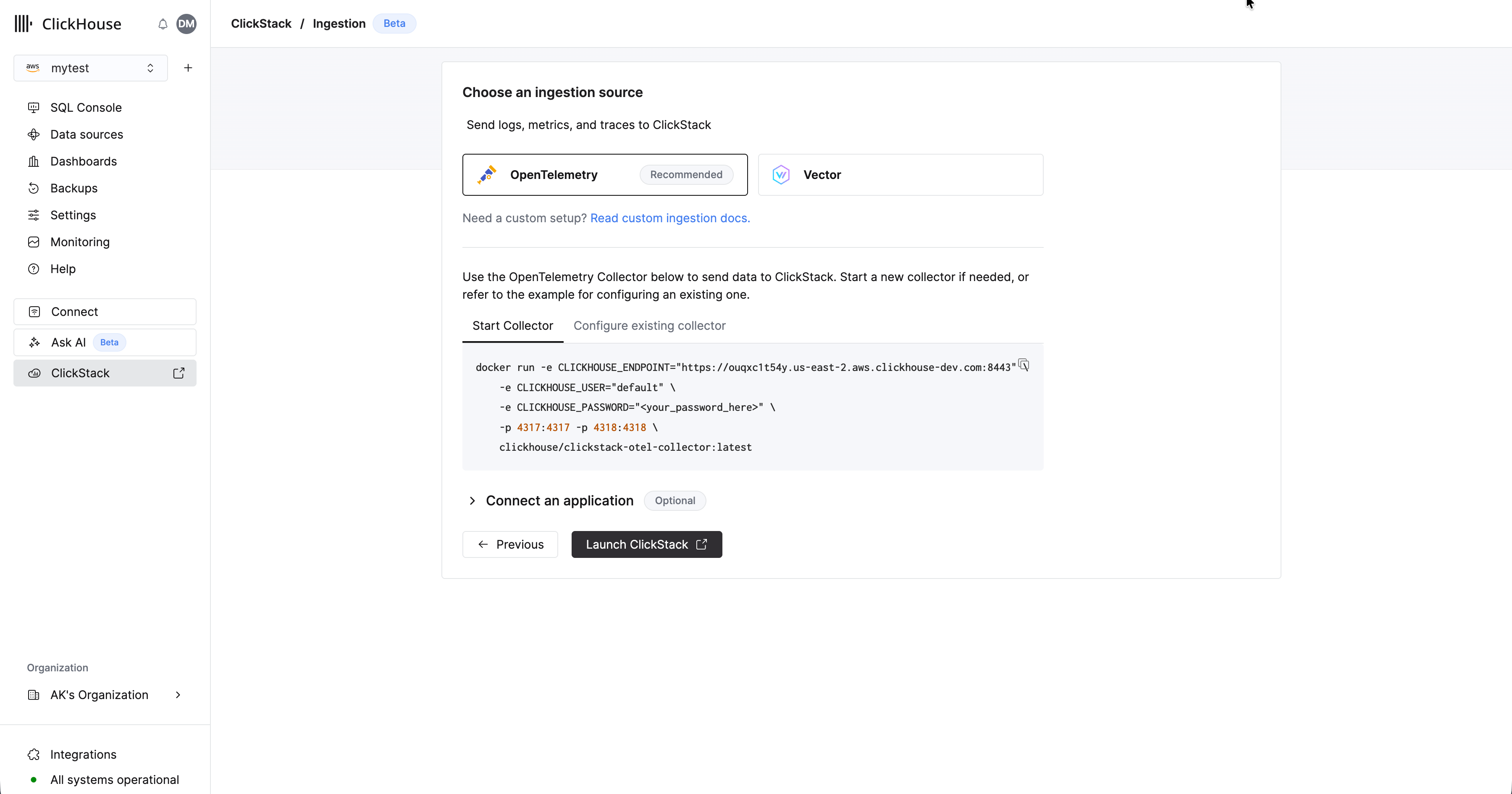
Использование формата OpenTelemetry настоятельно рекомендуется для ингестии. Он обеспечивает самый простой и оптимизированный рабочий процесс с готовыми схемами, которые специально спроектированы для эффективной работы с ClickStack.
- OpenTelemetry
- Vector
Для отправки данных OpenTelemetry в управляемый ClickStack рекомендуется использовать OpenTelemetry Collector. Коллектор действует как шлюз, принимающий данные OpenTelemetry от ваших приложений (и других коллекторов) и передающий их в ClickHouse Cloud.
Если у вас еще не запущен коллектор, запустите его, выполнив приведенные ниже шаги. Если у вас уже есть работающие коллекторы, также предоставлен пример конфигурации.
Запустите коллектор
Далее предполагается рекомендуемый подход с использованием дистрибутива OpenTelemetry Collector от ClickStack, который включает дополнительную обработку и оптимизирован специально для ClickHouse Cloud. Если вы планируете использовать собственный OpenTelemetry Collector, см. раздел "Настройка существующих коллекторов."
Чтобы быстро начать работу, скопируйте и выполните показанную команду Docker.
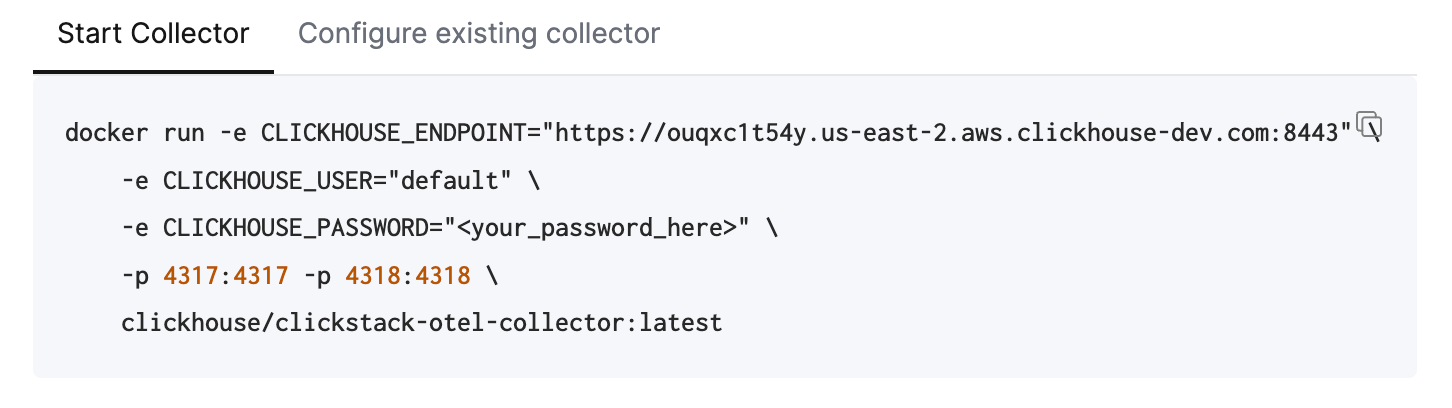
Эта команда будет содержать предварительно заполненные учетные данные для подключения.
Хотя эта команда использует пользователя default для подключения к Managed ClickStack, при переходе в production следует создать отдельного пользователя и изменить конфигурацию.
Выполнение этой команды запускает коллектор ClickStack с конечными точками OTLP, доступными на портах 4317 (gRPC) и 4318 (HTTP). Если у вас уже настроены инструментация и агенты OpenTelemetry, вы можете сразу начать отправку телеметрических данных на эти конечные точки.
Настройте существующие коллекторы
Также можно настроить собственные существующие коллекторы OpenTelemetry или использовать собственный дистрибутив коллектора.
Если вы используете собственный дистрибутив, например contrib-образ, убедитесь, что он включает экспортер ClickHouse.
Для этого предоставлен пример конфигурации OpenTelemetry Collector, использующий экспортер ClickHouse с соответствующими настройками и предоставляющий OTLP-приемники. Данная конфигурация соответствует интерфейсам и поведению, ожидаемым дистрибутивом ClickStack.
Пример этой конфигурации приведён ниже (переменные окружения будут предзаполнены при копировании из интерфейса пользователя):
Для получения дополнительной информации по настройке коллекторов OpenTelemetry см. раздел "Ingesting with OpenTelemetry."
Запустите процесс ингестии (необязательно)
Если у вас есть существующие приложения или инфраструктура, которые нужно инструментировать с помощью OpenTelemetry, перейдите к соответствующим руководствам, на которые есть ссылки в UI.
Чтобы инструментировать приложения для сбора трассировок и логов, используйте поддерживаемые языковые SDKs, которые отправляют данные в ваш OpenTelemetry Collector, выступающий шлюзом для приёма данных в Managed ClickStack.
Логи можно собирать с помощью OpenTelemetry Collectors, запущенных в режиме агента и перенаправляющих данные в тот же коллектор. Для мониторинга Kubernetes используйте специальное руководство. Для других интеграций см. наши руководства по быстрому старту.
Демонстрационные данные
В качестве альтернативы, если у вас нет существующих данных, попробуйте один из наших тестовых наборов данных.
- Пример набора данных — загрузите пример набора данных из нашего публичного демо и продиагностируйте простую проблему.
- Локальные файлы и метрики — загрузите локальные файлы и отслеживайте состояние системы под управлением OSX или Linux, используя локальный OTel collector.
Vector — это высокопроизводительный, независимый от вендора конвейер данных для обсервабилити, особенно популярный для ингестии логов благодаря своей гибкости и низким требованиям к ресурсам.
При использовании Vector с ClickStack пользователи сами отвечают за определение собственных схем. Эти схемы могут соответствовать соглашениям OpenTelemetry, но также могут быть полностью настраиваемыми, представляя пользовательские структуры событий.
Единственное строгое требование для Managed ClickStack заключается в том, что данные должны содержать столбец временной метки (или эквивалентное поле времени), который можно задать при настройке источника данных в ClickStack UI.
Далее предполагается, что у вас уже запущен экземпляр Vector, предварительно настроенный с конвейерами ингестии, которые доставляют данные.
Создайте базу данных и таблицу
Vector требует, чтобы таблица и схема были определены до начала ингестии данных.
Сначала создайте базу данных. Это можно сделать через консоль ClickHouse Cloud.
Например, создайте базу данных для логов:
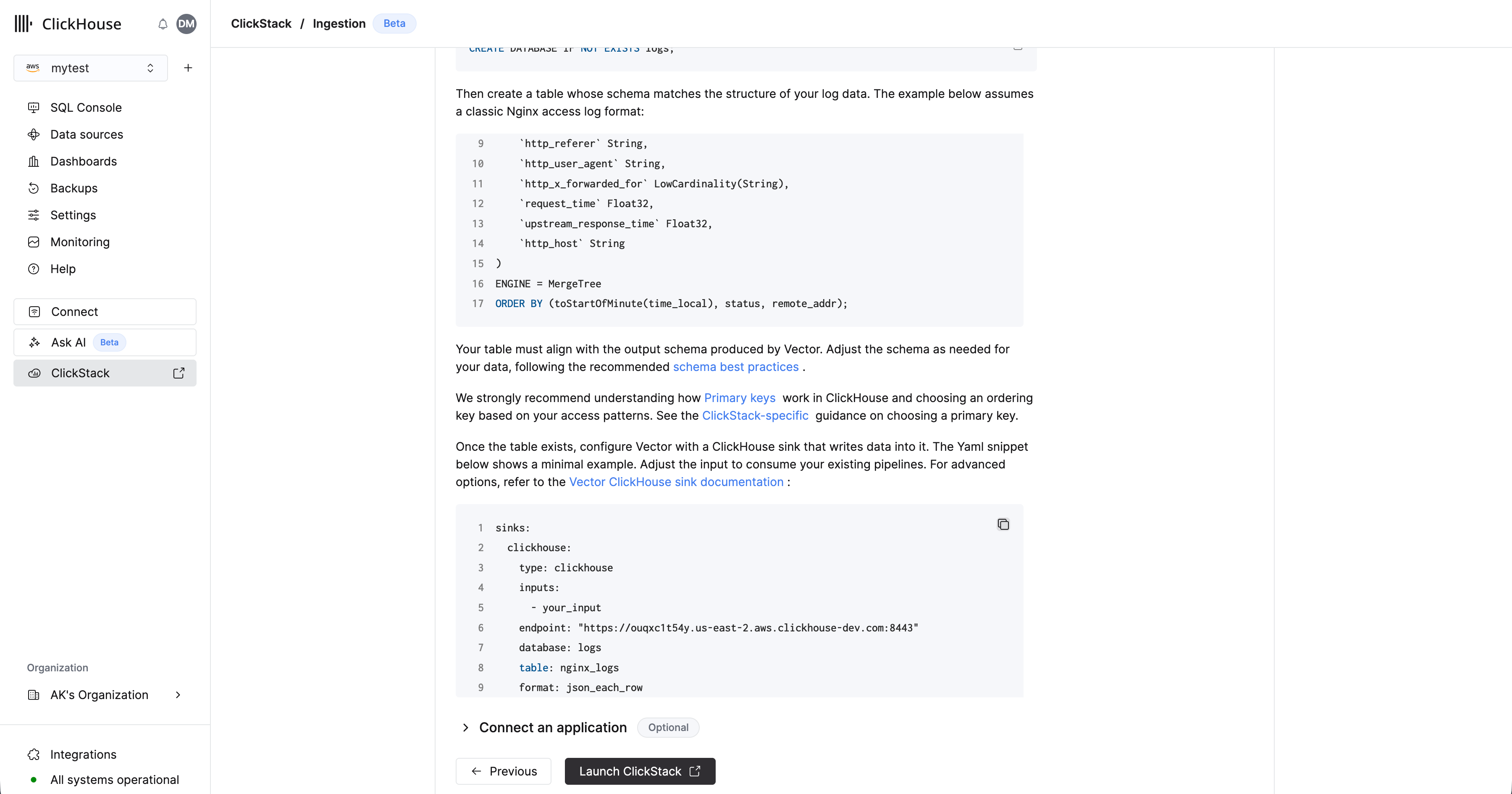
Затем создайте таблицу со схемой, соответствующей структуре ваших логов. В приведённом ниже примере используется классический формат access-логов Nginx:
Ваша таблица должна соответствовать результирующей схеме, создаваемой Vector. При необходимости скорректируйте схему под ваши данные, следуя рекомендуемым практикам по выбору схемы.
Настоятельно рекомендуется разобраться, как работают Primary keys в ClickHouse, и выбрать ключ сортировки на основе ваших сценариев доступа. См. также рекомендации специфичные для ClickStack по выбору первичного ключа.
После создания таблицы скопируйте показанный фрагмент конфигурации. Скорректируйте input, чтобы он использовал ваши существующие пайплайны, а также целевую таблицу и базу данных при необходимости. Учетные данные будут предзаполнены.
Для получения дополнительных примеров приёма данных с помощью Vector см. "Ingesting with Vector" или документацию по приёмнику ClickHouse для Vector для расширенных возможностей настройки.
Перейдите в интерфейс ClickStack
Выберите 'Launch ClickStack', чтобы открыть UI ClickStack (HyperDX). Вы будете автоматически аутентифицированы и перенаправлены.
- OpenTelemetry
- Vector
Источники данных будут предварительно созданы для любых данных OpenTelemetry.
Если вы используете Vector, вам потребуется создать собственные источники данных. При первом входе вам будет предложено создать один. Ниже приведён пример конфигурации источника данных для логов.
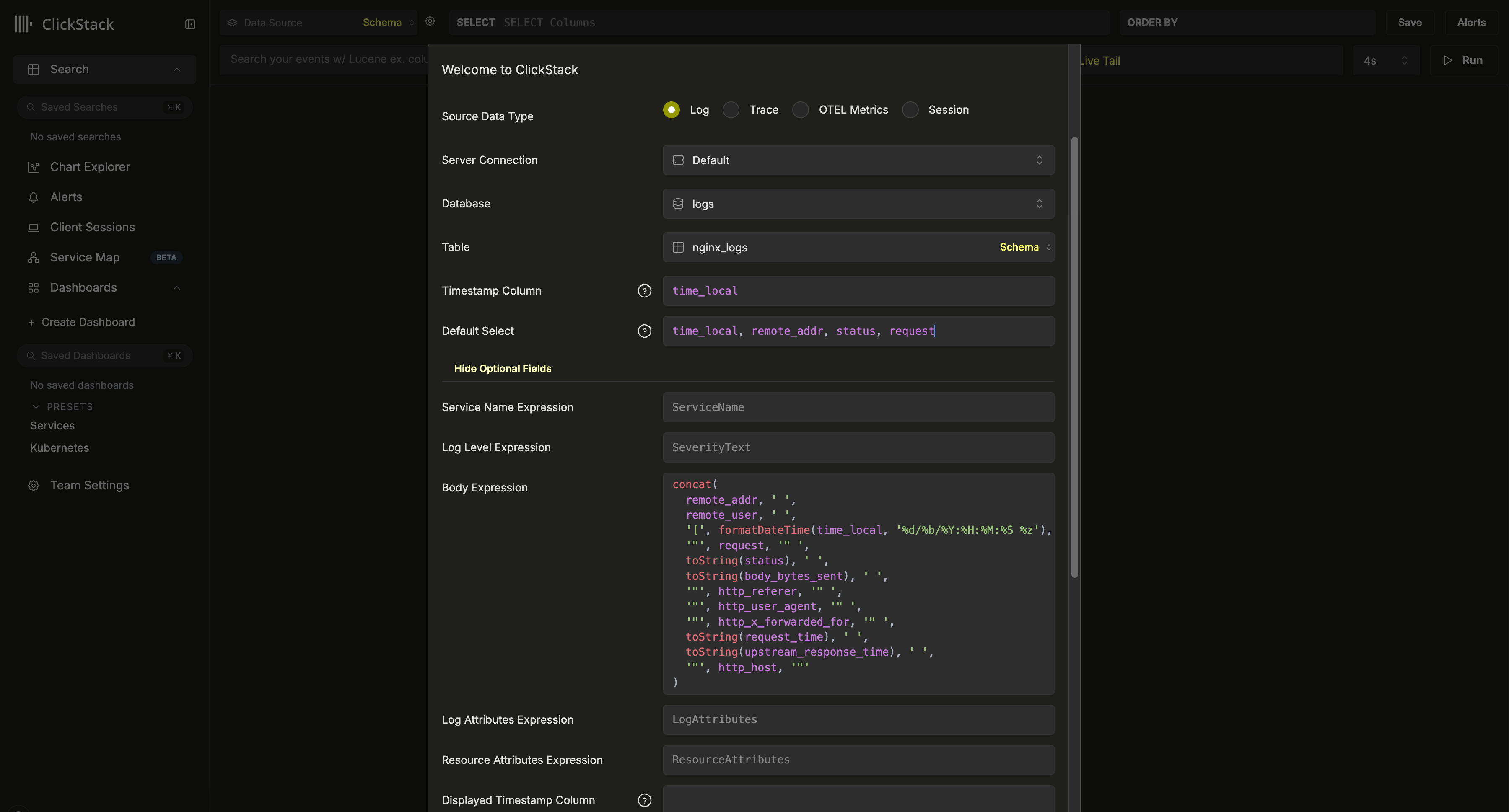
В этой конфигурации предполагается схема в стиле Nginx с использованием столбца time_local в качестве временной метки. По возможности это должен быть столбец временной метки, объявленный в первичном ключе. Этот столбец обязателен.
Мы также рекомендуем обновить Default SELECT, чтобы явно определить, какие столбцы возвращаются в представлении логов. Если доступны дополнительные поля, такие как имя сервиса, уровень логирования или столбец с телом сообщения, их также можно настроить. Столбец отображения временной метки также может быть переопределён, если он отличается от столбца, используемого в первичном ключе таблицы и настроенного выше.
В приведённом выше примере столбец Body в данных отсутствует. Вместо этого он определяется с помощью SQL-выражения, которое реконструирует строку лога Nginx из доступных полей.
Другие возможные варианты см. в справочнике по конфигурации.
После создания вы будете перенаправлены в представление поиска, где сможете сразу начать исследовать свои данные.
Вот и всё — вы готовы к работе. 🎉
Исследуйте ClickStack: начинайте поиск по логам и трейсам, смотрите, как логи, трейсы и метрики коррелируют в режиме реального времени, создавайте дашборды, изучайте карты сервисов, выявляйте дельты и паттерны событий и настраивайте алерты, чтобы опережать инциденты.
Дальнейшие шаги
Если вы не записали свои учётные данные по умолчанию на предыдущих шагах, перейдите к сервису и выберите Connect, зафиксировав пароль и HTTP- и native-эндпоинты. Сохраните эти административные учётные данные в надёжном месте — их можно будет повторно использовать в следующих руководствах.
Для выполнения задач, таких как создание новых пользователей или добавление дополнительных источников данных, см. руководство по развёртыванию Managed ClickStack.
