DataStore: API chDB, совместимый с pandas и оптимизированный для SQL
DataStore — это API chDB, совместимый с pandas, который сочетает привычный интерфейс pandas DataFrame с мощью оптимизации SQL‑запросов и позволяет писать код в стиле pandas, получая производительность ClickHouse.
Ключевые возможности
- Совместимость с pandas: 209 методов pandas DataFrame, 56 методов
.str, более 42 методов.dt - Оптимизация SQL: операции автоматически компилируются в оптимизированные SQL-запросы
- Ленивые вычисления: выполнение операций откладывается до момента, когда требуются результаты
- Более 630 методов API: обширный API для работы с данными
- Расширения ClickHouse: дополнительные аксессоры (
.arr,.json,.url,.ip,.geo), недоступные в pandas
Архитектура
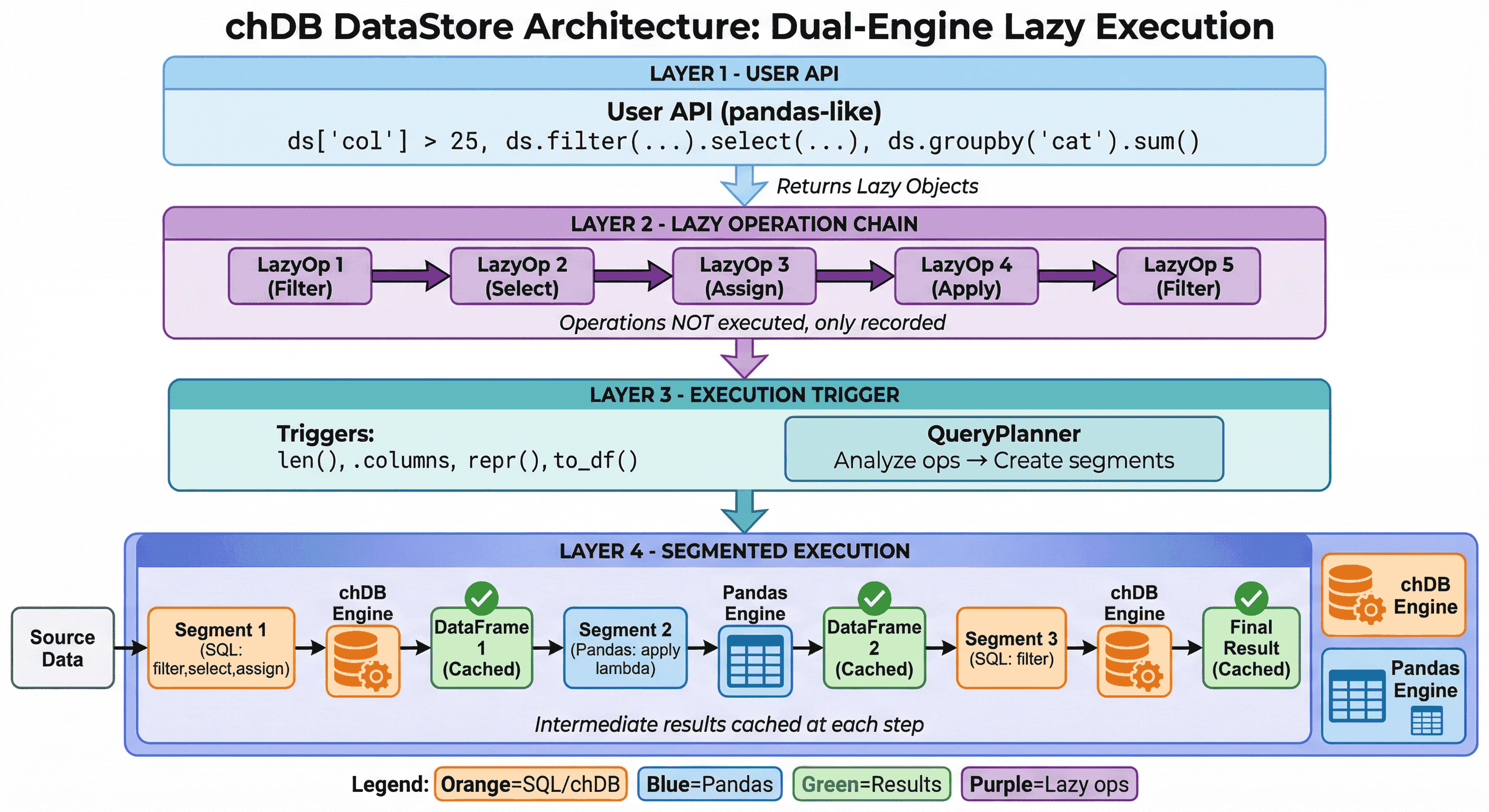
DataStore использует отложенные вычисления с двухдвижковой архитектурой выполнения:
- Отложенная цепочка операций: операции записываются, но не выполняются немедленно
- Интеллектуальный выбор движка: QueryPlanner направляет каждый сегмент в оптимальный движок (chDB для SQL, Pandas для сложных операций)
- Промежуточное кэширование: результаты кэшируются на каждом шаге для быстрого итеративного исследования данных
Подробности см. в разделе Модель выполнения.
Миграция из Pandas одной строкой
Ваш существующий код pandas работает без изменений, но теперь выполняется поверх движка ClickHouse.
Сравнение производительности
DataStore обеспечивает значительный прирост производительности по сравнению с pandas, особенно для агрегаций и сложных пайплайнов:
| Операция | Pandas | DataStore | Ускорение |
|---|---|---|---|
| GroupBy count | 347ms | 17ms | 19.93x |
| Complex pipeline | 2,047ms | 380ms | 5.39x |
| Filter+Sort+Head | 1,537ms | 350ms | 4.40x |
| GroupBy agg | 406ms | 141ms | 2.88x |
Бенчмарк на 10M строк. Подробности см. в скрипте бенчмарка и руководстве по производительности.
Когда использовать DataStore
Используйте DataStore, когда:
- Работаете с большими наборами данных (миллионы строк)
- Выполняете агрегирование и операции groupby
- Выполняете запросы к данным из файлов, баз данных или облачных хранилищ
- Строите сложные конвейеры обработки данных
- Вам нужен API pandas с более высокой производительностью
Используйте raw SQL API, когда:
- Вы предпочитаете писать SQL напрямую
- Вам нужен точный контроль над выполнением запроса
- Работаете с функциями ClickHouse, которые недоступны через API pandas
Сравнение возможностей
| Возможность | Pandas | Polars | DuckDB | DataStore |
|---|---|---|---|---|
| Совместимость с API Pandas | - | Частичная | Нет | Полная |
| Отложенные вычисления | Нет | Да | Да | Да |
| Поддержка SQL-запросов | Нет | Да | Да | Да |
| Функции ClickHouse | Нет | Нет | Нет | Да |
| Методы доступа к строкам/DateTime | Да | Да | Нет | Да + дополнительные возможности |
| Array/JSON/URL/IP/Geo | Нет | Частично | Нет | Да |
| Прямые запросы к файлам | Нет | Да | Да | Да |
| Поддержка облачных хранилищ | Нет | Ограниченная поддержка | Да | Да |
Статистика API
| Категория | Количество | Покрытие |
|---|---|---|
| Методы DataFrame | 209 | 100% API pandas |
| Аксессор Series.str | 56 | 100% API pandas |
| Аксессор Series.dt | 42+ | 100%+ (включая дополнительные возможности ClickHouse) |
| Аксессор Series.arr | 37 | Специфичный для ClickHouse |
| Аксессор Series.json | 13 | Специфичный для ClickHouse |
| Аксессор Series.url | 15 | Специфичный для ClickHouse |
| Аксессор Series.ip | 9 | Специфичный для ClickHouse |
| Аксессор Series.geo | 14 | Специфичный для ClickHouse |
| Всего методов API | 630+ | - |
Навигация по документации
Начало работы
- Быстрый старт - Установка и базовое использование
- Миграция с Pandas - Пошаговое руководство по переходу с Pandas
Справочник по API
- Factory Methods - Фабричные методы для создания DataStore из различных источников
- Query Building - Операции построения запросов в стиле SQL
- Pandas Compatibility - Все 209 методов, совместимых с pandas
- Accessors - аксессоры для String, DateTime, Array, JSON, URL, IP, Geo
- Aggregation - агрегатные и оконные функции
- I/O Operations - чтение и запись данных
Продвинутые темы
- Модель выполнения - Ленивые вычисления и кэширование
- Справочник классов - Полный справочник по API
Конфигурация и отладка
- Конфигурация - Все параметры конфигурации
- Режим производительности - режим, ориентированный на SQL, для максимальной пропускной способности
- Отладка - EXPLAIN, профилирование и логирование
Руководства для пользователей pandas
- Pandas Cookbook - Распространённые приёмы
- Key Differences - Важные отличия от pandas
- Performance Guide - Руководство по оптимизации производительности
- SQL for Pandas Users - Понимание SQL, лежащего в основе операций pandas
Краткий пример
Следующие шаги
- Впервые используете DataStore? Начните с краткого руководства по началу работе
- Переходите с pandas? Ознакомьтесь с руководством по миграции
- Хотите узнать больше? Изучите справочник API
